CSAPP笔记01信息的表示和处理
CSAPP笔记01信息的表示和处理
CSAPP(Computer System:A Programmer’s Perspective),是一本有关计算机组成原理的书籍,被誉为价比等重黄金。接下来的一些列博客将会是此书的读书笔记。这本书的内容比较广泛,对于比较基础的部分将不会记录或者简要记录,只记录那些以前遗漏的重要的知识和方法。书中有例题,每章结束后有大量homework,太简单的题目就不记录了。另外,书中结合c语言来进行讲解,有关c语言的特性和技巧不是本博客的记录范围。
0x00 本章概述
现代计算机以二进制信号来储存信息,每个二进制数字成为位bit,孤立的位没啥用,但是组合在一起的位,再加上某种解释,就可以表示任何有限集合的元素,比如字符和数字。
计算机中关于数字的表示方法有三种,无符号数,有符号数和浮点数,前两者都用来表示整数。无符号数用原码表示,也就是将大于等于0的整数直接用二进制来储存,而有符号数则既可以表示负数又可以表示非负数。浮点数则是将小数以类似于以2为底的科学计数法的形式表示。
上述三种表示,都是用指定大小的二进制位表示,所以能够表示的数是有一定的范围的,如果数组太大,则无法表示,称为溢出。
数字在计算机内部的计算,整数是准确表示的,因此满足数学中整数的运算性质,如乘法的交换律和结合律。但浮点数则并非如此,浮点数是不精确的,因此不满足交换律和结合律。
为了使编写的程序能够在全部数值范围内工作,并且具有跨域不同机器、操作系统和编译器的可移植性,需要充分了解计算机有关数字和字符的编码的特性。
0x01 信息储存
计算机内部,以8个位(一个字节byte)作为最小的可寻址单位,cpu将内存视为一个非常大的字节数组,成为虚拟内存,每个字节都有一个唯一的数字来标识,即该字节的虚拟/线性地址,所有可能的地址的集合就成为虚拟地址空间,之所以成为虚拟,是因为主存DRAM、磁盘、操作系统及特殊硬件将代码要访问的地址转换后才能访问到物理内存。
C语言中的指针的值,是一个某个储存块(也就是字节序列)的起始虚拟地址,并且指针还保存着该储存快对应的类型。
数据大小
每台计算机都有一个字长(word size),指示指针数据的标称大小(norminal size),所以字长决定了虚拟地址空间的最大大小。字长位N的机器上,虚拟地址范围是0-2^N-1。
主流的机器字长是32或64位,大多数32位机器上编译的程序可以在64位机器上运行,对于gcc,可以使用以下命令指定目标机器字长:
linux>gcc -m32 test.c //-m64
我们称32位程序和64位程序主要是依据该程序编译时的目标平台字长,而不是运行时机器的类型。
计算机和编译器支持多种不同方式编码的数字格式,如不同长度的整数和浮点数,如下图是c语言各种数据类型分配的字节数:
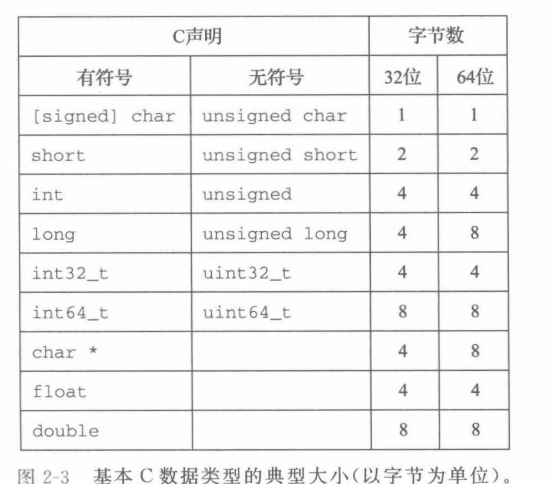
可以看到long和指针类型的长度都由编译时的目标平台决定,c语言为了避免数据类型长度依赖目标平台,引入了int32_t和int64_t这两种类型,是确定大小的整数类型。
大部分数据类型都编码为有符号的,如果不确定可以给其加上前缀signed(有符号)或者unsigned(无符号)。
我们应该力图使我们的程序能够在不同的机器和编译器上可移植,要求程序对不同的数据类型的确切大小不敏感。
字节顺序
对于连续(线性空间上的连续)使用多个字节的数据,我们必要要知道,这个对象的地址是什么,长度多少,以及如何排列这些字节。
对于数字的储存,有两种主流的排列顺序,即大端法(big endian)和小端法(little endian)。后者将数字的高位对应的字节,放在地址空间的高位,数字的低位对应的字节,放在地址空间的低位;而前者则相反。
字符编码
c语言中的字符串被编码为一个以null(值为0)字符结尾的字符数组,每个字符都由某个标准编码给出,最常见的是ASCII字符码(只能表示英语字母和少数符号,每个字符占1字节),其余的编码标准还有Unicode、UTF-8等
布尔代数
布尔代数是对命题的逻辑运算,对应于计算机中,是位运算,两个二进制位运算的结果如下:
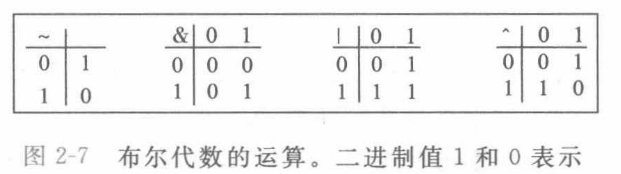
我们将上述运算扩展到了位向量的运算,比如一个字节对另一个字节进行上述取反 与 或 亦或运算,结果是。。。
逻辑运算
| C语言中还提供了一组逻辑运算符 ** | && !分别对应命题逻辑中的OR AND NOT**运算,逻辑运算很容易和位运算搞混淆,逻辑运算认为所有非零的参数都是TRUE(C语言中等于1),而参数0表示FALSE,他们的运算结果只能是0或者1,分别表示FALSE和TRUE。 |
移位运算
C语言中还提供了移位运算,将整数对应的二进制位整体左移或者右移的模式。
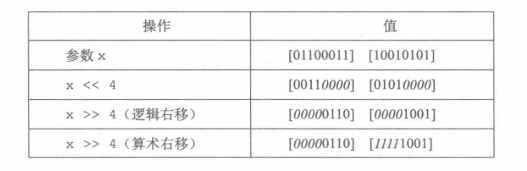
对于无符号数,是逻辑位移(也就是如果要填充就填0),对于有符号数,左移是逻辑的,而右移则是算数的(也就是右移时如果要填充,则填充符号位,确保正负号不变)。
0x02 整数的表示
无论是无符号数,整数的大小是
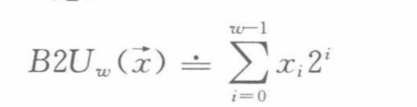
对于有符号数,整数的大小是
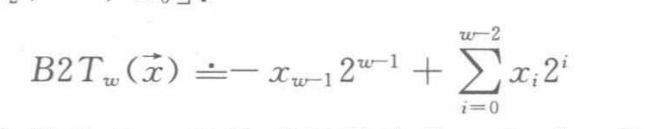
无符号数和有符号数之间的转换
C语言允许各种不同的数字数据类型之间的转换。有强制转换和隐式转换两种情况。
首先,无符号与无符号运算的结果总是无符号数,所以对于unsigned a,b而言 a-b>=0,总是恒成立的,不论a,b为何值。
对于同等字长之间的转换(比如从4字节的int转换到unsigned int),数值可能会变,但是二进制位不变
因此等长的 无符号数转换到有符号数的结果是:(Tmax是有符号范围内的最大值)
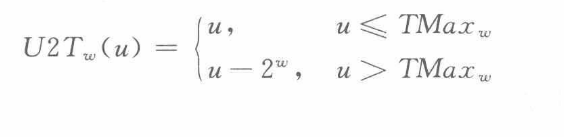
有符号数转换到无符号数的结果是:
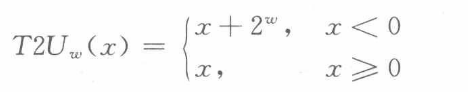
当一种类型的表达式赋值给另一种类型时,就发生了隐式转换,使用(int)等可以强制转换。
int tx,ty;
unsigned ux,uy;//unsigned 即使unsigned int
tx=(int)ux;//强制类型转换
ty=y;//隐式类型转换
扩展和截断数字
对于无符号数,将其从较小字节扩展到较大字节,总是在高位加0即可,而对于有符号数,则是添加原来长度的符号位。这样才能维持数值不变。
而对于减少一个数字的位数(也就是截断位数)而言,无符号数是单纯的将高位扔掉,如将unsigned int转换成unsigned short,那么直接用低16为即可。
而如果是有符号数的int->short,则是另一种情况,先将有符号数转换成无符号数,按照上面无符号数的截断方法截断,最后将截断后的数转换成有符号数(看作)。
整数的运算
加法:对于加法而言,不论是有符号数还是无符号数都要担心是否溢出(cross/overflow)。但是两者的范围不同,决定了溢出的情况也不同
无符号数的加法:
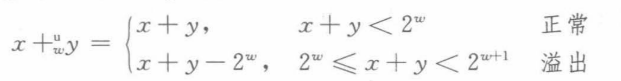
溢出检测,如果unsigned a,b a+b<a, 即发生溢出
有符号数的加法:
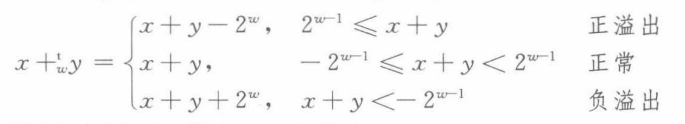
溢出检测,如果int a,b a>0 b>0 a+b<0,溢出 a<0 b<0 ,a+b>0 溢出
对于有符号数,减去一个数并不一定等于加上其相反数,因为对于Tmin(有符号数里最小数,比如signed char里是-128),其相反数是自身,因为计算机里的相反数是用的和为0,-128为1000 0000,要想和为0,还要加1000 0000,因此自身为自身的相反数
乘法
无符号数乘法,就是防溢出:
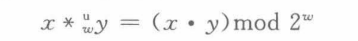
有符号同样是防止溢出:
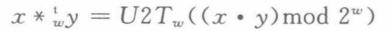
溢出检测,乘法的溢出检测比较简单,假定x*y=z,那么如果x=z/y即可认定未溢出,反之溢出。
乘常数可以分解成位运算,比如x*31 <=> (x«5)-x,编译器一般会自动优化。 同样除2的幂,也可以用向右位移来优化
除2的幂的舍入规则!
需要注意的是,5/2=2,可以理解,因为最右边的1右移1位后没了,而-5/2也=-2,这就很不可理解了,为啥呢?假定是signed char 那么-5=》1111 1011 右移1位表示除2 =》 1111 1101,这结果明明是-3啊!,其实原因是当为负数时会结果+1,为了保证 a/b=-(-a/b)
0x03 浮点数
浮点数对形如V=x * 2 ^ y的有理数编码,它能表示非常大的数字、非常接近0的数字,以及更普遍地作为实数运算的近似值。
先考虑有小数值的二进制数字:
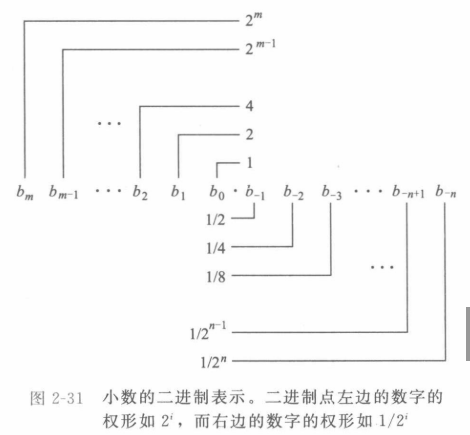
可以看到小数点左侧的权是2的正幂,右边是负幂,十进制表示法不能准确地表达像1/3和5/7这样的数,同样二进制小数对于某些数也只能近似表示,增加二进制表示的长度可以提高表示的精度。
IEEE浮点数
用V=(-1)^s * M * 2^E来表示一个数字:
符号(sign) s决定这个数的正负,对于数值0的符号位解释作为特殊情况。
尾数(significand)M 是一个二进制小数,它的范围是[1,2-x],或者是[0,1-x],(x由具体编码决定)
阶码(exponent)E的作用是对浮点数加权,这个权重是2^E(E可能是负数)。
将浮点数的位表示划分为三个字段,分别对这些值进行编码。C语言中,有两种常见的浮点数格式,单精度浮点数(float) 双精度浮点数(double),编码的格式如下:

s是符号位 exp是阶码,frac是尾数。其中阶码又分为以下三种情况:
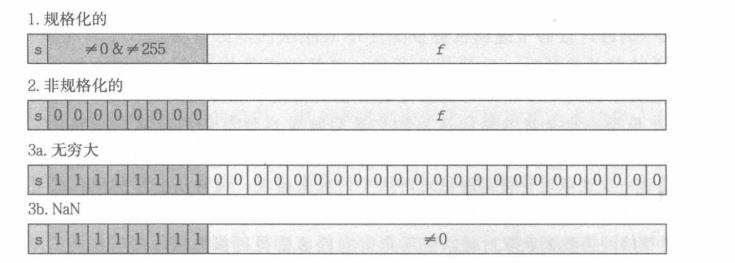
规格化的阶码:即非0也非全1,这个时候阶码的值E=e-Bias 这个Bias是偏置,Bias=2^(k-1)-1 k是阶码的位数,比如单精度浮点数中的8位阶码,那么Bias=2^7-1=127,因此 单精度浮点数中阶码E的范围是[-126,127] (因为e是1-254)。在规格化的阶码中,尾数是二进制的小数部分,最后结果要+1,也就是将尾数看作:
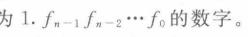
非规格化的阶码:阶码全0时,用来表示非常接近0的数,这个时候阶码的值位1-Bias,同样的Bias也是偏置2^(K-1)-1,比如单精度浮点数中的8位阶码,那么Bias=127,因此此时阶码的值是-126,按道理说这个时候的阶码应该是0-Bias啊,之所以这样是因为尾数此是:
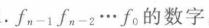
没有加1,因此这个时候可以和规格化的阶码所表示的小数连续起来。比如单精度浮点数中,规格化所能表示的最小的正数是 (1+0) * 2^-126 而非规格化的能表示的最大正数是 (1-x) * 2 ^ (-126),x是2^(-23) 23是尾数的位数。
特殊值阶码,也就是阶码全1,此时尾数域要么全为0,则表示无穷大,如果符号为正(即0),即正无穷,如果符号位为负(1)即负无穷;如果尾数不为0,则为NaN不是实数。比如表示sqrt(-1)。
浮点数在数轴上的分布如下:
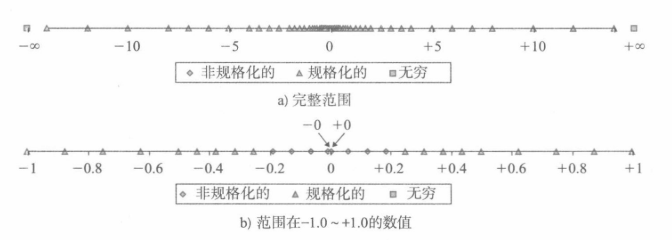
可以看到,非规格化的浮点数,表示的是非常接近0的数。
将整数12345编码成单精度浮点数12345.0,12345=1.1000000111001(二进制小数) * 2 ^13,因此 我们的尾数是 .1000000111001,而阶码是13,因此e-Bias=13,Bias=127,因此阶码上应该是140的二进制编码,符号位为0 正数。因此12345.0的单精度浮点数编码为:0_10001100_1000000111001_0000000000。
测试题

2^(Y+1)+1 因为尾数的增长的最小单位是2^(-Y),如果不能准确表示,说明尾数即使最小增长,* 阶码后增长的范围大于1,那么 2^ E *2 ^(-Y)>1,因此E=Y+1,所以此时阶数是Y+1,但是2^(Y+1)是能够准确表示的(让尾数为0,阶码为Y+1即可),所以第一个不能准确表达的是2^(Y+1)+1
舍入 因为浮点数只能近似的表达实数,因此,对于值x,我们一般相处一种系统的方法,找到最接近的匹配值x’,并将x’用期望的浮点数表示出来。
有四种舍入方法: 向偶数舍入(相当于10进制的四舍五入) 向0舍入(抹掉有效值之外的位) 向下舍入 向上舍入
用向偶数舍入(四舍五入)主要是为了不影响统计学上的平均值。
浮点数运算
浮点数运算和普通整数运算的结果类似,但是任意运算,计算的结果将会被舍入到浮点数。当然对浮点数的精确计算是开销是很大的,而浮点运算单元的设计者们,一开始就不打算让浮点单元得出准确的结果,而是保证一定的有效位数,让舍入后的结果和准确计算后舍入的结果一样即可。
定义了1/-0产生-∞ 1/+0 产生+∞(浮点数中0有正负之分)。
浮点数的加法不具有结合性,因此对于如下的运算:
x=a+b+c
y=b+c+d
如果是整数运算,编译器可能会优化如下:
t=b+c
x=a+t
y=t+d
这样运算结果不变,将少一个加法运算,但是对于浮点数,这样优化后结果将改变,编译器倾向于保守,不改变代码的任何功能,因此浮点数不会这样优化
浮点数乘法运算具有可交换,但是不可结合。
即a * b=b * a 但是 a *(b+c)不等于 a * b + a * c
