cs143一
0x00 lexical Anaysis
work:①seperate string into words ②classify words ,such as identifier、keyword、number、whitespace
fundamention:① scan left to right ②look ahead
result:token (pairs of class name and string)
means: regular language .five model :single character\ epsilon (blank or absent or empty)\ union (a∪b) \concatenation ( a∩b) \lteration (a*)
0x01 how to identify a token
construct each token’s regular expression and match them
0x02 how to seperate a string into words
①combining all token’s regular expression with union,match string prefix step by step.Once match a token,remove the prefix. ②If there are several token which match different prefix at the same string, we should use the maximal prefix’s token(such as == math “=” the same as “==”).③ sometimes,there may be two or more tokens match the same prefix,so we shoud specify the priority of tokens.keywords always prior then identifier.④when there is no rule match,we should handle the error to give a nice feedback to programmer.
0X03 DFA vs NFA
dfa: deterministic finite automata nfa: nondeterministic finite automa
What is finite automata: ①a set of state ② a set of input ③no block(can always reach end state)
what is dfa: ①a input match only one transition ② no epsilon transition(must have input then trans)
what is nfa:oppsite to dfa
the fundamental different between dfa and nfa is whether they can accept epsilion transition.(multitransition can consist of epsilion tansition) nfa can choose while dfa can not,one input match one transition.So for one certaion input string,dfa move on one path while nfa’s possible path form a tree.For one step,nfa locate a set of state while dfa locate a accurcy state. If a input sequence can reach the final state, both dfa and nfa can reach the state, but dfa is faster than nfa,because dfa has only one path.
0x04 implement lexical specification
As we talk above,we just anaysis the regular expression for lexical specification but do not talk how to implemnt it.there are several step:
①translate regular expression to nfa ②use dfa than nfa
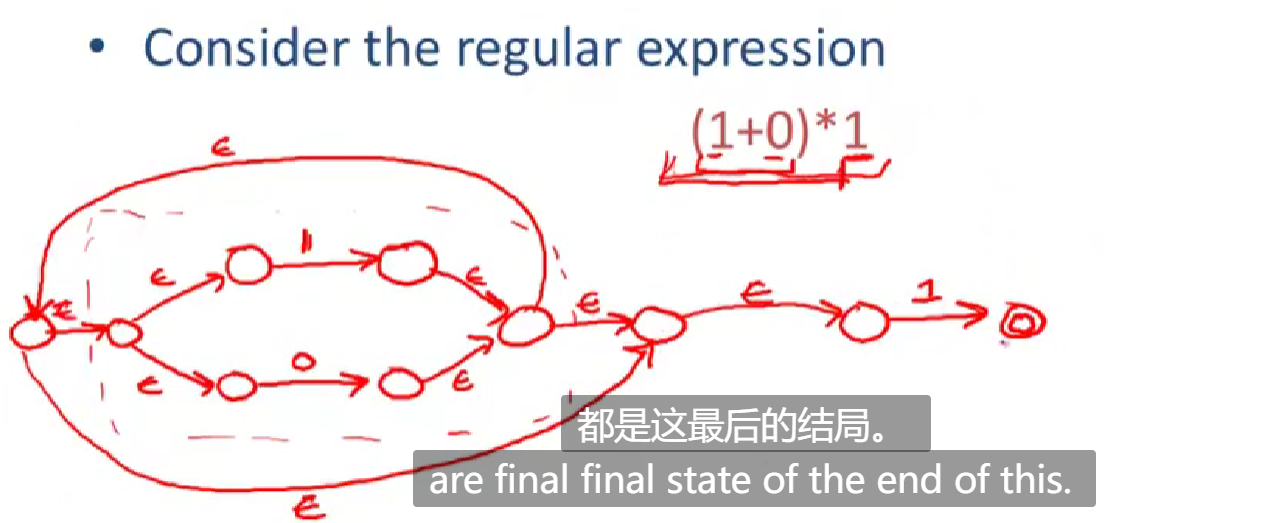
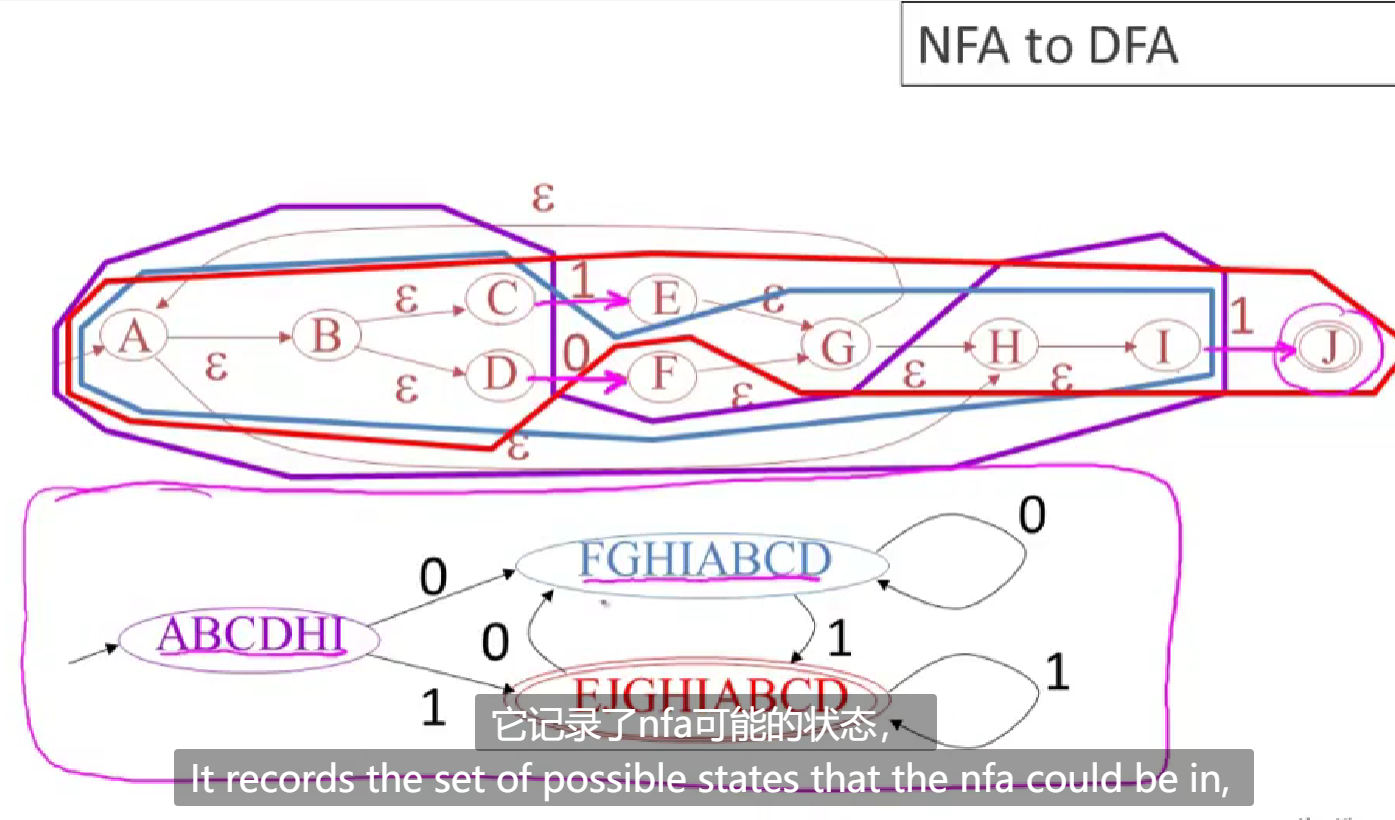
0x05 how to transfer a nfa model to dfa
there some definition:

for a finited automata,S is the set of all states for certain input sequence. s
is the start state.obviously s is substate of S. F is the final state,which is also a substate of S. The Operator a(x) definite a set of state in which x can transfer to when accept input a. **epsilon-closure ** is a set of state which s can reach without any input besides epsilon.
for a nodeterministic finited automata, it’s states must be subset of S,because nfa have multi-state at a input while dfa has only one. And dfa ‘s start state is e-closure(s) .It is easy to understand that in a e-closure,there need no input to transfer,so all the states in e-closure is the start state in dfa. For final state,dfa just need to reach a subset of nfa’s final states. The operator **e-closure(a(x)) ** is a set which accept a input a to tansfer to another state and use closure to expand all states it include.
0x06 a simple model for FA
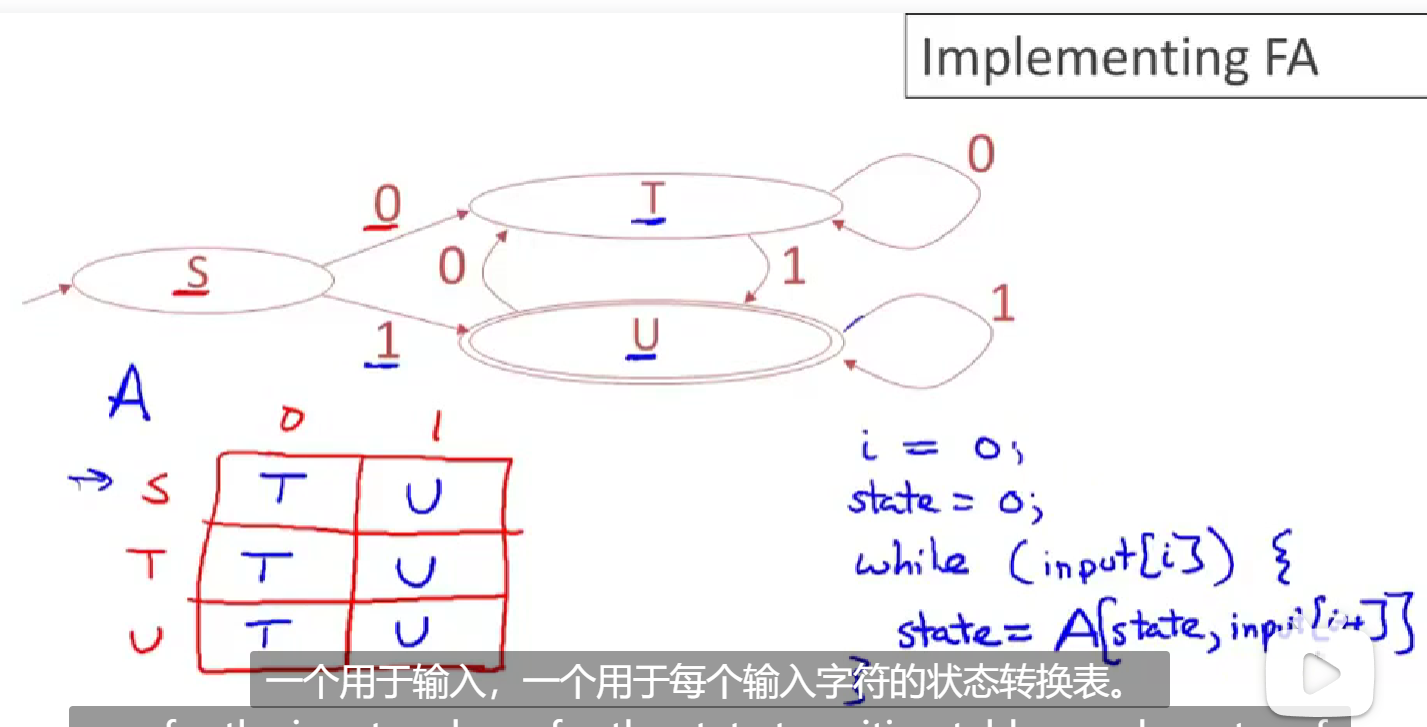
As depicted above,We use a 2-dimension table to store states and the transition when they accept input.For a input consquence we just refer the table in a loop.
But as we can see,it has many repeated row,so we can merge the same row to only one, and use pointer to indicate it in table.
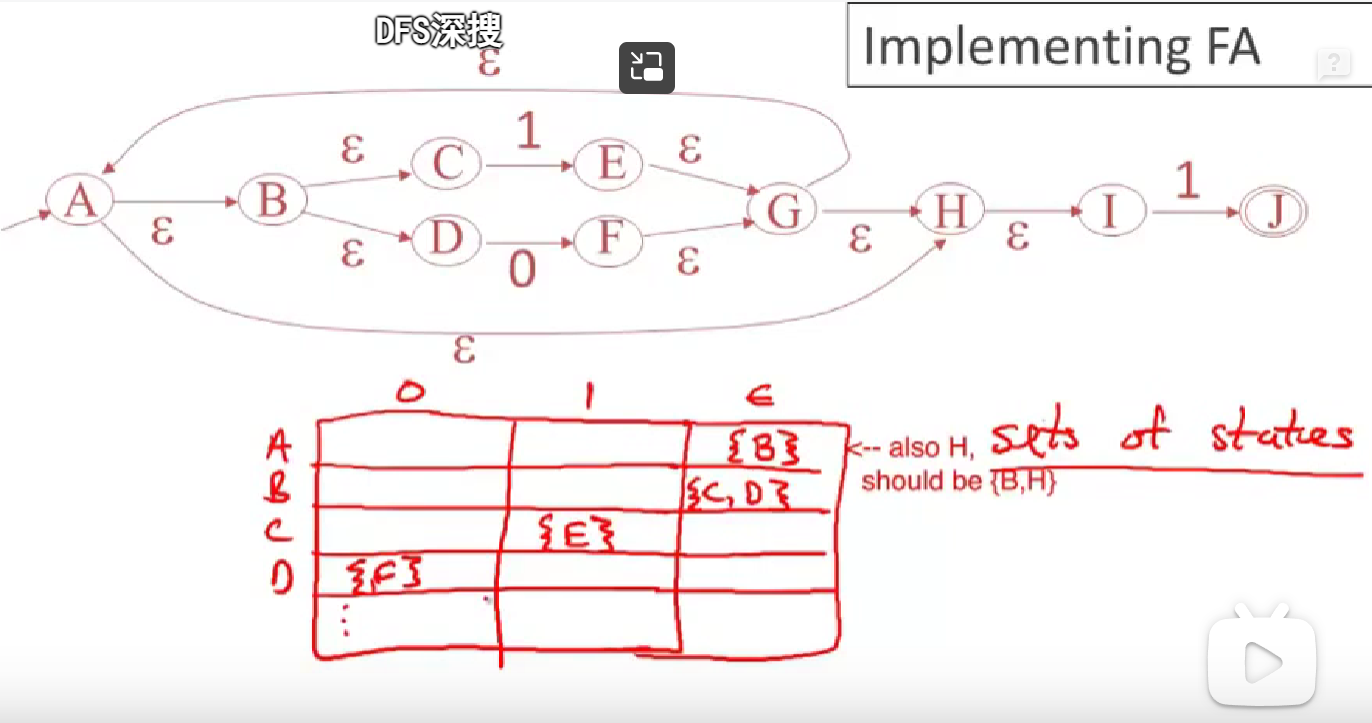
As for nfa, there are more than one state after receive a input or epsilon, so is is a set of state rather than a single state in certain step which bring huge complexsity and cost more time.
0x07 summery
This blog record the lexical anaysis part of compier.It is a pity that there is not a achieve of dfa or nfa.The pa of this part use flex rather than implemnt it by our code.I will upload my work to my github repocs143 assignment.Wait for your watch.
