CSAPP笔记05异常控制流(上)
CSAPP笔记05异常控制流(上)
0x00 概述
从处理器加电到断电,程序计数器(PC)的一个值序列(a0,a1..an),其中an是某个指令的地址,每次从ak->ak+1的过渡称为控制转移,这个序列为控制流。
一般的控制流都是平滑的,即每个指令都是相邻的或者由程序本身的要求实现的跳转、调用和返回。
而计算机系统不同层级的、突然的状态变化,需要不同层级的程序来处理。
现代系统通过使控制流发生突变来处理这些情况,我们称为异常控制流(Exception Control Flow)。异常控制流发生在计算机系统的各个层次:
硬件层次:处理器检测到异常,执行相应的异常处理。
操作系统层次:内核通过上下文切换,将控制转移到另一个进程。
应用层次:一个进程之间可以发送信号到另一个进程,接受者会将控制转移到它的信号处理程序;程序可以无视函数调用的栈规则(先入后出),执行任意跳转来对错误做出反应。
0x01 异常
异常是异常控制流的一种形式,一部分由硬件实现,另一部分由软件实现。异常的作用是,对处理器的状态变化做出反应。
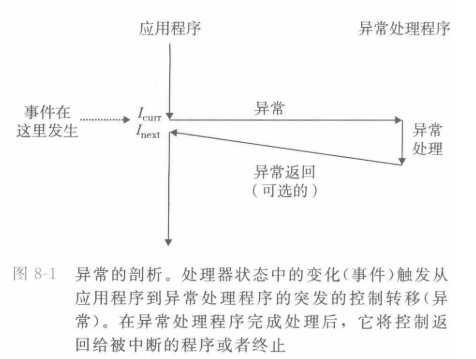
状态的变化称为事件,事件可能和当前执行的指令有关(缺页、除0、溢出),也可能无关(外部输入)。
处理器检测到事件后,通过一个跳转表—异常表(对应IDT,interruption descriptor table),进行一个间接过程调用,调用对应的异常处理程序。异常处理程序执行完毕后,会返回:
①可能会回到跳转前的下一条指令
②可能会回到跳转前的那一条指令重新执行
③可能会终止被中断(打断)的程序
这些可能与引起异常的事件有关,下面具体介绍。
异常处理
引起异常的不同事件被编号,称为异常号,处理器分配一部分异常号,操作系统内核也分配一部分(内核是操作系统常驻内存的那部分)。
处理器分配的异常号的事件:被零除、缺页、内存访问非法
内核分配的异常号的事件:系统调用、外部IO
计算机启动后,内核在内存里维护一张异常表,这个表中记录了不同异常号的异常处理程序的跳转地址等信息,用IDTR(interruption descriptor table register)寄存器来保存该表的物理地址。
当处理器检测到异常事件,会根据异常号访问该表中的对应条目,然后调用对应的异常处理程序,处理完后用iret指令返回。异常处理程序是内核模式,而返回后回到用户模式(如果调用前是用户模式)。
异常处理程序和普通的函数调用类似,也会返回,并且也在栈里保存状态和返回地址,也有些不同:
①异常处理程序返回后,不一定会返回到调用前的下一条指令。
②异常处理程序调用时会压flag寄存器入栈 if tf=0 push flag (push cs) push ip
③异常处理程序工作在内核模式下,指令权限更大,并且使用内核栈,而不是用户栈(防止栈溢出)。
异常的类别
异常事件分为细分为中断、陷阱、故障、终止。
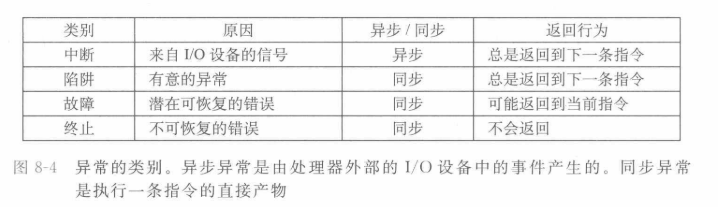
①中断,中断是外部I/O信号事件,因为不由指令引起,因此是异步的(即任何时候都可以产生中断事件),中断必定回到调用前的下一条指令。
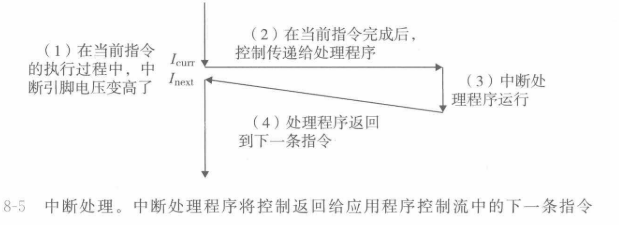
②陷阱,陷阱是指令主动发起的事件(syscall),用于系统调用,即用户模式的代码调用内核模式的代码,比如读一个文件、创建一个进程,终止当前进程,都需要用户程序调用系统调用,同样是回到下一条指令。
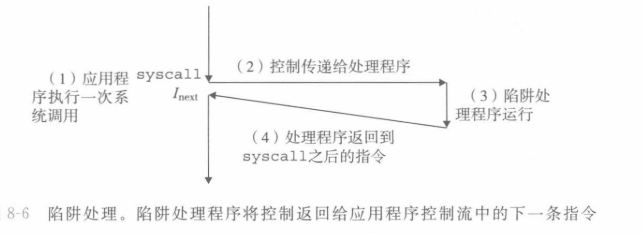
③故障,故障是指令执行时的错误,因此调用故障处理程序来解决。典型的故障,比如缺页(即访问的虚拟地址没有被分配或者没有缓存)。故障处理程序返回后,一般会返回到引起故障的那一条指令,重新执行!要是故障解决不了,也可能直接结束程序。
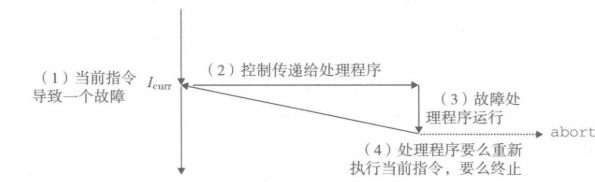
④终止,终止是不可恢复的致命错误,通常是硬件错误,将直接终止程序。
linux中的故障、终止和陷阱
故障:
①除法错误(linux不会试着解决这个故障,而是直接终止程序)
②一般性保护故障,段越界(一般不会,平坦模型),违背段的读写属性,违背页的读写属性,页未被分配,会引起段故障
③缺页,已经分配了磁盘也,但是没有缓存到主存。
终止:
①硬件错误,直接终止程序。
系统调用:
c标准库将系统调用进行了包装,方便我们使用,我们将系统调用和包装函数都称为系统级函数。
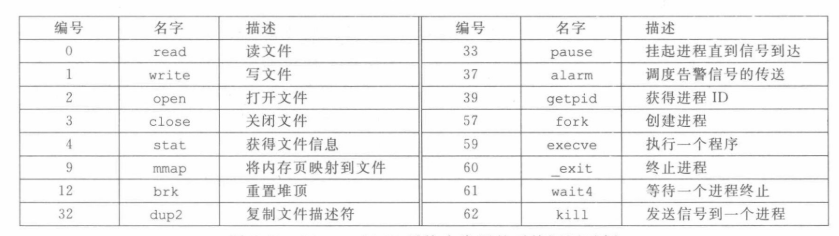
x86-64系统上,系统调用(陷阱)通过syscall指令发起(汇编指令),参数只用寄存器传递,%rax传递的是功能号。常见的系统调用如下,编号即是功能号:
0x02 进程
异常中的中断机制,允许操作系统内核提供进程机制(process)。中断实现了抢占式任务切换。
进程是一个执行中的程序的示例(定义),每个程序都运行在某个进程的上下文(context)中。上下文是程序正确运行所需要的状态组成,(即TSS,task state segment),包括存放在内存中的代码和数据,段寄存器,通用寄存器,以及打开的文件描述符等。
进程给应用程序提供了一个独立的逻辑控制流,进程给应用程序提供了一个私有的地址空间。
逻辑控制流
操作系统中通常有许多程序在运行,通过进程的定时切换,好像每个程序都在独占地使用处理器,每个进程都有自己地指令的地址序列,我们将进程的指令的地址序列称为进程的逻辑控制流。
同样的,经过进一步的分时复用,进程逻辑流又可分割成线程逻辑流。
逻辑流就是一段连续的指令的地址的合集,虽然这些指令在时间上不是连续运行的,但是效果可以看作连续运行的。
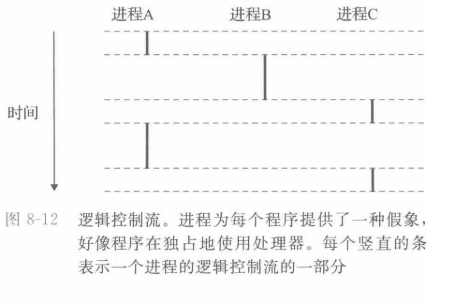
并发流
实际上逻辑流有许多形式,异常处理程序、进程、信号处理程序、线程等都算逻辑流。
如果一个逻辑流的执行在时间上与另一个流重叠(也就是开始时间和结束时间之间的重叠,而不是真的同时,毕竟是分时复用的,除非多核处理器或者超线程技术),称为并发流(concurent flow),这种现象称为并发(concurency)。
如果两个流真的同一时刻都在运行(多核处理器或者超线程技术),那么称为并行流(parallel flow),这种现象称为并行(parallation)。
也就是并行是实现并发手段的一种。
私有地址空间
进程为程序提供一种假象,好像在独占地使用系统地址空间。一般而言,一个进程的地址空间对应的字节是不能被其他进程读写的,因此称为私有地址空间。
操作系统为每个进程的地址空间设计了固定的结构:
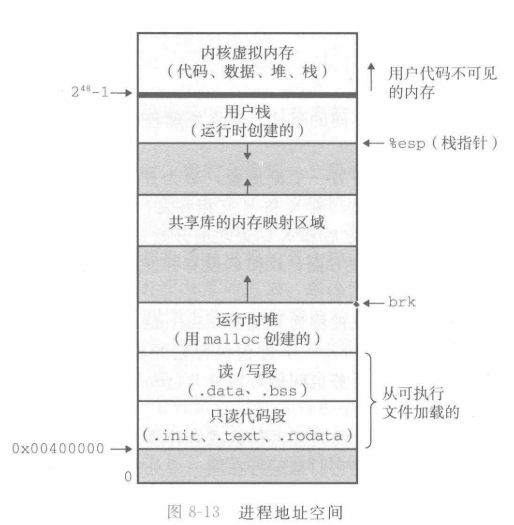
地址空间的顶部留给内核,这样才能在不同进程中调用系统调用。
用户模式和内核模式
私有地址空间是操作系统通过指令实现的,为了完全杜绝用户程序访问其他进程的私有地址空间可能性,要限制用户程序能够执行的指令和访问的地址空间。
但是内核应该不受这种限制,他要能操作不同的进程的私有地址空间,以实现管理功能。
因此处理器设置某个控制寄存器(control register,CR),来提供这种功能(设置cr0的0位,进入保护模式,通过cs寄存器的段描述符选择子低2位来设置当前特权级CPL current privilege level)。
如果特权级为0,则是内核模式,为3在用户模式。
注意,用户模式和内核模式的转换,仍在当前进程中。
上下文切换
操作系统通过上下文切换来实现进程切换,也就是用TSS来保存一个应用运行时的所有信息,如果要切换任务,就保存旧任务的状态到它的TSS,然后通过新任务的TSS,恢复新任务的上下文,最后将跳转给新任务的CS:IP处。
在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个之前被抢占的进程,称为调度(scheduling),由内核中的调度器(scheduler)处理。
当内核代表用户程序执行系统调用时,内核可能会进行调度,切换到其他进程。比如一个进程调用read访问磁盘,在等待数据返回的时候,内核可以决定切换到另一个进程,高效地利用处理器。
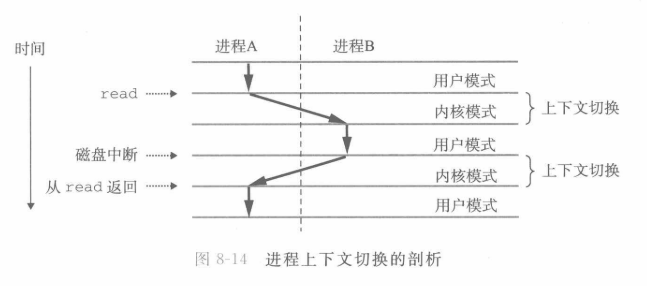
即 A进程用户态调用系统调用->A进程的内核态,内核代理A进程执行调用,内核出于某种原因决定调度B进程->B进程的内核态(实际上TR寄存器切换TSS选择子)->B进程的TSS恢复CS:IP切换到用户态。
0x03 系统调用错误处理
linux系统中,使用系统即函数(系统调用或者被包装后的函数),如果出现错误,那么它们的返回值为-1,同时会设置全局整数变量errno。当使用系统调用后,总应该检查其返回值,如果为-1,那么用strerror(errno)函数,可以获得有关错误的具体信息的字符串。
(fprintf 第一个参数是输出流,如果要输出到终端,就直接stdout)

为了自定义错误描述,我们定义以下的错误报告函数:

然后在需要的地址,就能简单的使用:
最后,我们直接将处理了错误信息的系统调用再次包装一下,形成包装函数:

以后,我们就直接调用Fork函数而不是fork。
0x04 进程控制
linux提供了大量操作进程的系统调用:
获取进程ID
每个进程都有唯一的进程ID,(process id ,PID).getpid()系统调用返回当前调用进程的PID, getppid()系统调用获取父进程的PID。
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
pid_t被types.h宏定义为int
创建和终止进程
一个进程总是处在下面三种状态之一:
运行:进制在被CPU执行或者等待CPU执行(注意等待执行也是运行状态)
停止:进程的执行被挂起(suspended,挂起就是暂停的意思),不会被cpu调度,但是可以重新恢复到运行状态。
当进程收到某些信号时,会暂停,收到某些信号时,又能再次开始运行。(信号是一种软件中断。)
终止:进程永远地停止,不再会恢复到运行状态。进程终止的三种原因:①调用exit()函数,②从main函数返回,③收到某些信号。
上面三种状态,可以用ps(process state)命令查看,加上-aux查看所有进程的状态,stat字段中的R即运行,S即停止/挂起(suspended),T即终止(terminated)
exit()函数用来终止进程,status参数用来设置退出状态
#include <stdlib.h>
void exit(int status);
fork()函数用来创建一个新的子进程
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
fork创建的子进程几乎与父进程完全相同,(这个问题的深入解释是,子进程复制了一份父进程的虚拟地址空间(页表)、物理内存、TSS、以及磁盘文件描述符)因为子进程将父进程的虚拟地址空间复制了一份,包括代码和数据、堆、共享库以及用户栈,并且还获得了父进程的打开的文件描述符的相同副本,因此子进程可以打开父进程中任何打开的文件。子进程和父进程的最大区别是,PID不同。
因此fork函数会返回两次!,在子进程中的代码中返回一次,父进程的代码中返回一次,因为它们的代码是一样的。但是在父进程中返回的是子进程的PID,而子进程中返回的是0(具体为什么子进程为0,太细节了,不深究)。
以下是fork使用的例子 

返回了两行,这两行分别是父进程和子进程返回的,子进程由于有父进程的打开了的文件的句柄,因此可以用的是父进程的stdout。
fork函数有以下几个特点:
①调用一次返回两次:一个fork比较好理解,但是有多个fork时,就要画图来理解了。
②并发执行:当调用fork创建子进程后,子进程和父进程都接受cpu调度,获得cpu的顺序由调度器决定。
③相同但是独立的地址空间:每个进程都有自己独立的私有地址空间,父进程和子进程也不例外,fork后,子进程的地址空间里的内容几乎与父进程完全相同(fork函数返回值不同,保存这个返回值的变量值不同,其余完全相同)。
④共享文件,即使连stdout也是共享的。
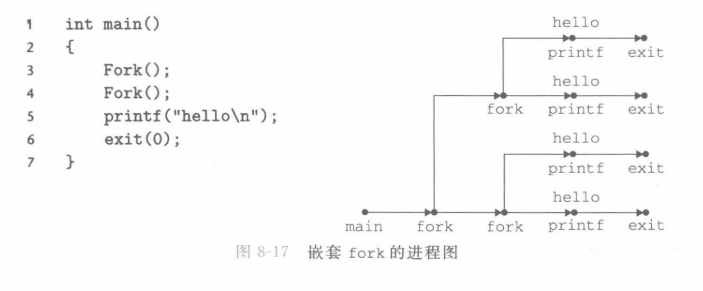
可以通过画拓朴图来更加清晰地认识各进程如何执行。
回收子进程
当一个进程终止时,内核并不是立刻将其从系统中清除。进程被保存在一种已终止的状态,直到被它的父进程回收(reaped,reap收获)。父进程回收已终止的子进程时,内核将子进程的退出状态(exit中的status就是这个,但是其他退出方式也产生对应的status),传递给父进程,然后才清除子进程。
一个终止了但是未被回收的进程称为僵尸进程(zombie)。
如果父进程终止了,内核会让init进程成为子进程的新的父进程(养父233),inti进程的pid是1,内核创建,不会终止。
如果父进程没有回收它的僵尸子进程就终止了,那么内核会安排init去回收,不过不是立刻。
僵尸进程对应于ps -aux命令中stat字段为Z的进程,(zombie)。
waitpid函数可以等待子进程终止或者停止。

pid参数可以填子进程的pid,或者-1,对应任意的子进程
status是一个int指针,用来返回子进程的退出状态
options用来修改waitpid的行为。默认行为,也就是options为0时,会将当前进程(也就是父进程)挂起(也就是当前进程状态变为停止),等待指定的子进程(-1时任意子进程)终止。
wait.h中定义了一些宏,用来检查子进程的退出状态:
如果调用进程没有子进程,那么waitpid直接返回-1,并将errno设置为ECHILD.
wait函数是waitpid的简化版,相当于waitpid(-1,&status,0)
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int*statusp);
注意,如果有多个子进程,使用-1来作为waitpid()的pid参数时,对子进程的回收顺序是不能确定的。如果想要按顺序回收,需要记录子进程的创建顺序,然后按照pid顺序使用waitpid
进程休眠/停止/挂起
sleep()函数将一个进程挂起一段指定的时间:
#include <unistd.h>
unsigned int sleep(unsigned int secs);
休眠指定时间后,进程恢复运行,此时sleep返回值为0。在sleep挂起线程的期间,如果收到信号,那么线程会恢复运行,sleep返回值为还剩下的休眠时间。
另一个是pause()函数,挂起进程,直到收到信号。(注意收到进程信号能够引起信号处理程序运行,但是某些信号能直接终止进程)
#include <unistd.h>
int pause(void);
加载并运行程序
execev()函数在当前进程的上下文中加载并运行一个新程序:
#include <unistd.h>
int execve(const char*filename,const char* argv[],const char*envp[]); //如果执行成功不返回,否则返回-1
execve函数加载并运行可执行目标文件filename,且带参数列表和环境变量列表,如果成功执行目标文件,那么接下来的所有代码都失效了,因为已经在进程内加载了新程序的代码,并自动跳到新程序的代码开头,只有执行失败,才会继续执行原来的代码。
参数列表和环境变量列表是用来传递给新程序地main函数的,实际上,我们以前写的main函数也可以接受:
int main(int argc,char**argv,char**envp);
参数列表argv是一个字符串数组,每个字符串以null结尾,并且按照惯例,argv[0]总是程序本身的名字,比如main.out。
环境变量envp也是一个字符串数组,但是每个串都是”name=value”的形式。
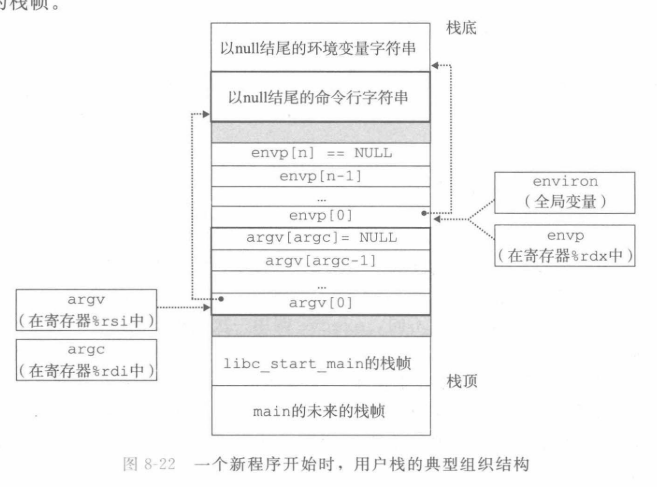
上图是程序开始的栈帧。
fork和execve结合
fork可以创建一个子进程,但是子进程的上下文几乎完全和父进程一样,如果子进程再用execve打开新程序,就实现了加载任意程序了。这正是shell和web服务器常做的事。
