从实模式到保护模式笔记6现代x86处理器编程架构
从实模式到保护模式笔记6现代x86处理器编程架构
本章开始进入保护模式的学习,知识点密集
0x00 IA-32架构的基本执行环境
IA-32处理器架构简称IA-32(intel architecture,32-bit),是以8086处理器为基础发展起来的,具有延续性和兼容性。32位处理器有32根地址线,数据线是32/64跟,可以访问2^32 即4GB的内存,每次可以读写连续的4字节或者8字节。
寄存器的扩展
16位的处理器内,有8个通用寄存器 AX BX CX DX SI DI SP BP,其中前四个还可以拆分成两个独立的8位来使用。而32位处理器则扩展了这8个寄存器的长度,达到32位
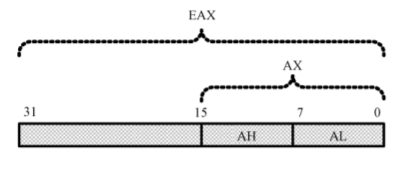
经过扩展的寄存器,命名为EAX EBX ECX EDX ESI EDI ESP EBP,即使工作在8086的实模式下,也可以访问: mov eax,0xf00000005,但是要注意 源操作数 和 目的操作数的 长度要匹配,都是32位(不够32位的立即数会被扩展成32位来匹配)
32位寄存器的高16位不能单独拿来使用,低16位可以正常使用。
32位处理器可以兼容8086的实模式,但是它有自己的模式称为32位保护模式,可以访问4GB的内存空间,32位保护模式下,使用的是被扩展的32位的EIP,同样无法直接修改,要通过JMP CALL RET等修改
同样32位保护模式下,FLAGS也被扩充成32位,低16位和原来作用保持一致。
理论上32位保护模式下不再需要分段,因为32根地址线可以访问到4GB内存的任何位置,但是IA-32架构是基于分段模型的,因此,即使工作在32位保护模式下依然以段为单位方位内存。对于必须要有一个段地址,有一种变通方案,即只划分一个段,段的基地址是0x00000000,段的长度是是4GB,可以视为不分段,即平坦模型
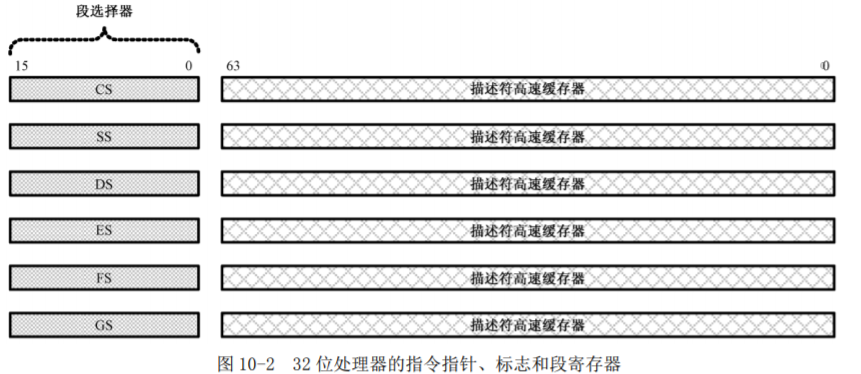
在16位模式下,程序可以通过修改段基地址自由地访问不属于它的内存位置,甚至可以修改,这很危险,但是没有基址来限制。在32位模式下,处理器会在内存的某个地方维护一个全局(段)描述符表(Global Descriptor Table)。
每项表头是段的选择子、 属性分别是真正的段地址,和程序大小等等属性。而程序加载时会在GDT里创建一个项,同时32位下,CS,DS,ES,SS等段寄存器 不再保存段地址,而是记录段的选择子(也就是GDT里的key码),和一个描述符高速缓存器(缓存段的选择子对应的属性, 保存在寄存器,免得经常查阅GDT)。程序不能访问和修改GDT和描述符高速缓存寄存器,处理器则用他们限制程序的内存访问。
基本的工作模式
8086只有一种工作模式,即实模式
80286提出了保护模式,但其本身仍然是16位,而地址线则是24位,因此很不方便,16位保护模式很少为人所知。所以后面所称的保护模式一般指32位保护模式
80386及后续所有的32位处理器都兼容实模式,刚加电时处于实模式,经过一番设置后可以处于32位的保护模式。保护模式下段的长度可以达到4GB,如果将4GB内存当一个段处理即是平坦模式,可以用偏移量访问任何位置。80386提供虚拟8086模式(不同于兼容的实模式,该模式是将寄存器拆分,一次模拟多个8086处理器),但是已经没什么用。
线性地址
内存分段是IA-32架构的特征之一。将段地址和偏移地址称为逻辑地址,而单独的偏移地址称为有效地址(因为32保护模式下平坦模型可以访问到全部地址,所以段地址为0,只看偏移地址就可以得出逻辑地址,因此称偏移地址为有效地址),而在指令中给出有效地址的方式称为寻址方式:
inc word [bx+si+0x06]
保护模式下,段的管理是由处理器的段部件负责进行的,无法应用程序无法访问和改变。段部件将段地址和偏移地址相加,得到访问内存的地址,一般来说,段不见产生的地址就是物理地址(如果没有开启分页)
IA-32处理器支持多任务,多任务下,物理内存中同时装在多个程序,任务的创建要分配内存空间,终止后要收回所占用的内存空间。在分段模型下,内存的分配是不定长的,大程序分配大空间,小程序分配小空间,一定时间后,可能会造成内存空间碎片化,即有空间,但都是小块的,无法分配给新程序。
分页功能解决了上述问题,分页功能将物理内存分为逻辑上的页,而页的大小是固定的,一般为4kb。当开始分页功能后,段部件产生的地址(逻辑地址)不再对应物理地址了,而是对应线性地址(2020-7-3补充,又称虚拟地址)。而线性地址经过页部件转换后,才对应物理地址。
也就是分页功能,给每个虚拟出了4GB线性连续的地址,这个地址称为连续地址,而连续地址再经页部件转换成真正的物理地址。分段和分页将在后续的章节详细展开。
0x01 现代处理器的结构和特点
流水线:将处理器执行一条指令分为 取指 译码 执行 三个过程,对应三个功能单元,如果这三个单元每次只处理一条指令,那么 同一时刻,只有一个功能单元在工作,处理一条指令要3个单位时间。而如果各个功能单元独立的并行地执行,像下面这样:
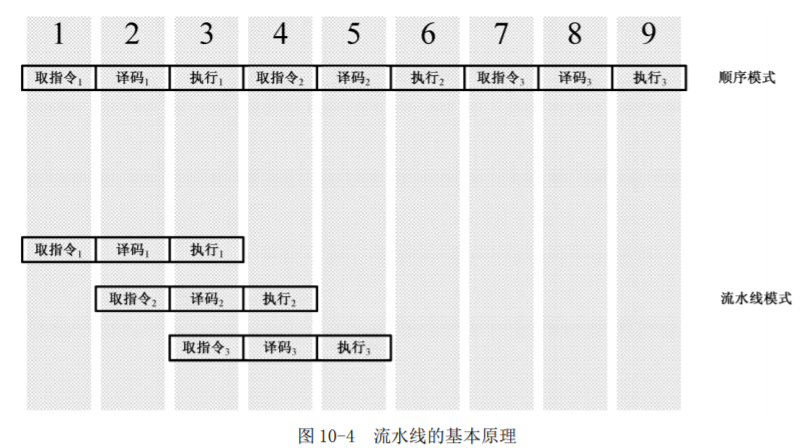
那么工作效率会快上很多。这种工作模式称为3级流水线。如果将指令执行分成更多的单元,那么就可以获得更长的流水线,效率也会大大提高。
高速缓存:寄存器的读取速度是最快的,因为它使用了触发器,且在处理器内部。触发器的工作速度在纳秒级,用它制成的储存器是SRAM(静态储存器),缺点是成本太高,而一般常用的内存是DRAM(动态储存器),访问速度是几十纳秒。而机器硬盘里的数据访问更慢,达到了毫秒级。
因为读写数据速度与cpu处理速度不匹配,处理器便无法高效运行。高速缓存应运而生,高速缓存是处理器与内存DRAM之间的一个静态储存器,容量较小,速度够快。
基于数据访问的规律:程序常常访问最近刚刚访问过的数据和指令或者与它们相邻的数据和指令。所以处理器将正在访问的和即将访问的指令和数据块从内存调入高速缓存。每当处理器要访问内存时,首先检索高速缓存,如果在高速缓存里,就以很快的速度取得,称为命中(hit),否则称为不中(miss),不中时,需要重新装载高速缓存,而不是直接去内存取,因此相对于没有高速缓存这一机制时,不中时访问数据速度更慢,损失的实践称为不中的惩罚(miss penalty)
高速缓存可能有多级,每个cpu实现不同
乱序执行:在实现流水线技术时,将指令拆分成更小的可独立执行部分,即微操作uo(micro-operations)uops,因此,处理器可以在必要的时候乱序执行(out of order):
mov eax,[mem1]
shl eax,5
add eax,[mem2]
mov [mem3],eax
由于add eax,[mem2]与前面的指令没有关系,因此在执行逻辑左移指令时,可提前从内存中读mem2的内容。如果mem1数据不在高速缓存,那么处理器会在获取mem1的内容之后,立即开始获取mem2的内容,于此同时shl指令的执行早就开始了。
寄存器重命名:
mov eax,[mem1]
shl eax,3
mov [mem2],eax
mov eax,[mem3]
add eax,2
mov [mem4],eax
虽然前面3句代码和后面3句代码都用了eax,但实际上我们可以看出 两部分完全无关,但是如果同时执行,eax的值又会冲突了,所以处理器为后面三条指令使用了一个不同的临时寄存器,因此上下两部分得以并行处理。
处理器内部有大量的临时寄存器可用,可以重命名这些寄存器以代表一个逻辑寄存器。寄存器重命名的工作方式非常简单,每当指令写逻辑寄存器时,就分配一个新的临时寄存器重命名代替之。又例如
mov eax,[mem1]
mov ebx,[mem2]
add ebx,eax
shl eax,3
现在假定mem1的内容在高速缓存里,可以立即取得,但mem2不在。因此,左位移可以在加法之前开始(使用临时寄存器代替eax进行左位移),左位移的结果也保存在临时的被重名了的寄存器里,真正的eax还是原来没有左位移的值,等到ebx的内容就绪,同它进行加法,如果没有重命名机制,左位移操作将不得不等待ebx寄存器内容就绪和加法操作完成。所有操作完成后,临时寄存器的值(经过左位移的值)写入真正的eax里,这个过程成为 引退(retriement)
所有的通用寄存器、栈指针 标志 浮点寄存器 段寄存器 都有可能被重命名
分支目标预测 如果遇到一条跳转指令,那么后面那些已经进入流水线的指令就失效了,称为清空(flush)流水线,要从转移的目标位置处重新取指放入流水线,这导致了效率的降低。
为了解决这一问题,引入了分支目标预测技术(branch predicition),分支预测的核心问题是,转移会不会发生,条件转移指令的条件成不成立。
单独的看这个问题,好像是不可能实现预测的,如果能提前直到条件指令执行的结果,那么还执行条件指令干嘛呢?但是从统计学的角度,有些事情一旦出现,下一次还会出现的概率较大,典型的例子就是循环,这就是分支目标预测的原理。(分支预测失败也是有惩罚的)
0x02 32位保护模式的指令系统
寻址方式
16位处理器的寻址方式:基址寄存器(bx/bp)+变址寄存器(si/di)+(idata偏移量8位/16位)
32位处理器处理器既可以运行在16位指令模式下,也可以运行在32位指令模式下。同时指令前缀0x66也决定采用的指令模式。即如果运行在16位指令模式下,没有前缀0x66 即使用16位模式的指令,如果有,则使用32位指令模式,同理在32位模式下也是如此,即认为0x66是模式反转前缀。
32位模式下的寻址方式为:基址寄存器(eax/ebx/ecx/edx/esp/ebp/esi/edi)+变址寄存器(eax/ebx/ecx/edx/ebp/esi/edi即除esp以外的32位通用寄存器都行) * 比例(1/2/4/8)+(idata偏移量8位/32位) 32位指令模式下立即数认为是32位
32位模式下,允许使用栈指针esp mov eax,esp 而16位模式指令下不允许 mov ax,[sp]
操作数的指令前缀
IA-32的指令格式: 前缀-操作码-寻址方式和操作数类型-立即数-偏移量
前缀是可选的 ,例如指令模式反转前缀 重复前缀 (rep/repe/repne) 段超越前缀 (es: ds: cs:)
操作码,指示将要经行什么操作:传送 加法 减法 乘法 除法 位移 操作码的长度是1-3个字节 同时操作码还可以指出要操作的字长 (比如push16位模式下默认2字节)
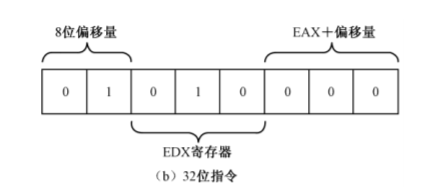
寻址方式和操作数类型,一般是1字节,是可选的 如16位模式下 mov dx,[bx+si+0x02] 其指令为 8b 50 02 ,8b是操作mov 50是寻址方式和操作数类型:
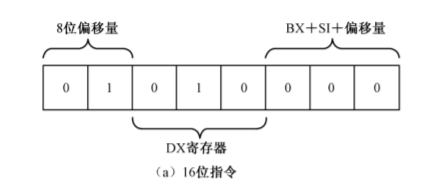
最后02 是偏移量
32位指令模式和16位指令模式的格式一样的都是上面的结构,但是解释和执行的效果不同,例如上图的 寻址方式和操作数类型部分50在32位指令模式下代表:
编译器提供伪指令bits 来指明程序被编译成16位模式的指令还是32位模式的指令,bits不能指定cpu到底是工作在16位还是32位!!(7-5补充:cpu如何看待编译出来的二进制指令是16位还是32位不是bits能决定的):
bits 16
mov cx,dx ;89 d1
mov eax,ebx ;66 89 d8
bits 32;或者[bits 32]也行
mov cx,dx ;66 89 d1
mov eax,ebx ;89 d8
16位指令模式是默认的编译模式。
一般指令的扩展
所有16位指令模式中以寄存器或者内存单元为操作数的指令都被扩充,以适应32位的算数逻辑操作。而且这些扩展的操作即使在16位模式下(bits 16)也是可以用的:
add al,bl
add ax,bx
add eax,ebx
add dword [ecx],0x0000005f
除了双操作数之另外,但操作数指令同样允许操作32位操作数。比如:
inc al
inc dword [0x2000]
dec dowrd [eax*2]
和16位模式下一样,逻辑移动指令的源操作数(移动位数)如果是寄存器的话,仍只能是cl:
shl eax,1
shl eax,9
shl dword [eax*2+0x08],cl
32位处理器不仅支持8 * 8 16 * 16 的乘法,也支持 32 * 32的乘法:(这是无符号乘法,有符号乘法和除法一样)
mov al,18
mov bl,10
mul bl;
mov ax,180
mov bx,100
mul bx;
mov eax,1800
mov ebx,1000
mul ebx;结果在edx:eax
32模式下的pop 和 push也有所扩展,允许压入双字操作数,另外它还支持压入立即数,这在16位中是无法直接实现额度
push byte imm8;(8位立即数)
psuh word imm16;(16位立即数)
push dword imm32;
但是注意,虽然写的是1字节,但是处理器任何个时候都不会真的压入1字节,而是在16位时将这个字节按照最高位扩展到16位(也就是当有符号数时不改变符号位),在32位时将这个字节按照最高位扩展到32位。
需要带上byte word dword等修饰字长的前缀,不然16位下默认时2个字节,16位下默认时4个字节。
0x03 题目检测

1.bits 32下0x66是反模式那么 mov bx,16需要带上0x66前缀 而mov ebx,16不用
2.虽然16位模式下的指令结构和32位下相同,但是具体的含义不同,bb 10 00分别是操作码 、寻址方式和操作数类型、立即数 32位下对10的寻址方式和操作数类型的解释和16位不同。
