基于markdown转html的nodejs博客系统
基于markdown转html的nodejs博客系统
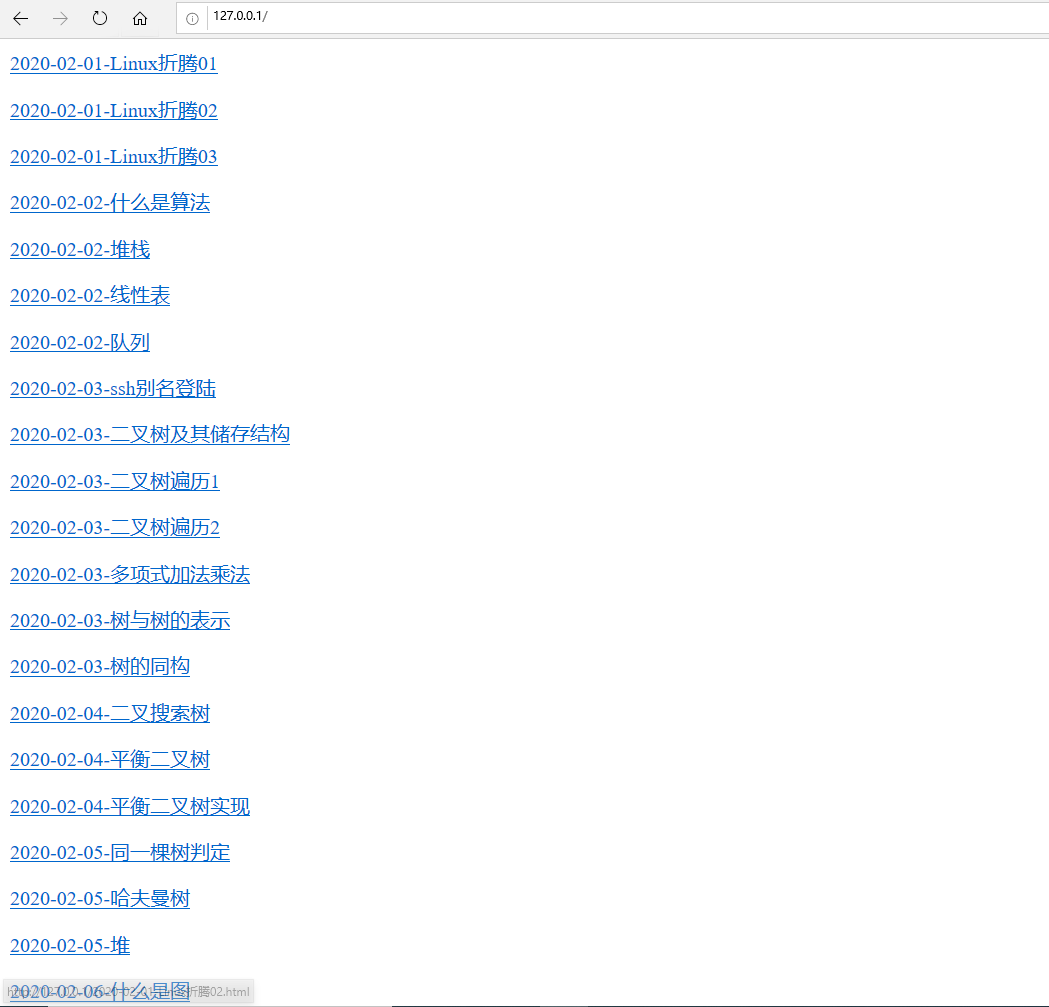
0x00 效果图
首页
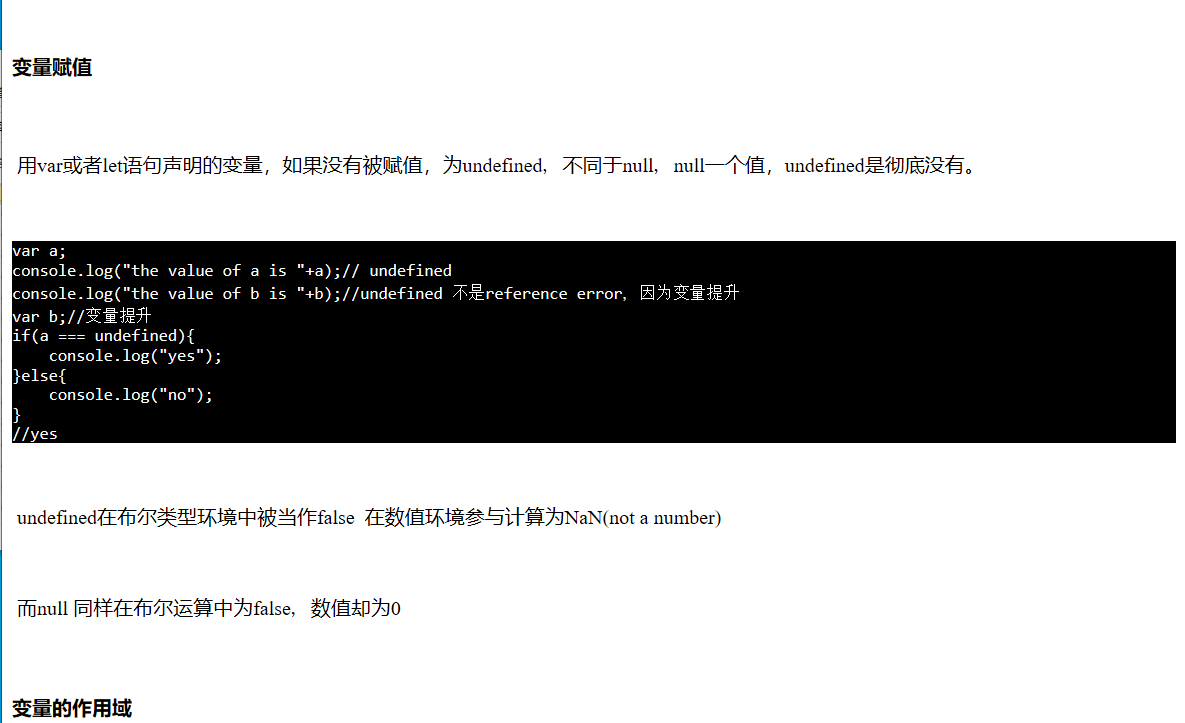
具体博客内容页面(没有懒得写css)
0x01 上代码!
1主要工作流程就是开启http服务器 然后读本地markdown文件 自动转成html页面保存在本地,浏览器请求就解析路由,如果是博客页面就看有没有,有就发博客html 和对应图片资源
2核心是mk转html,也只是几个基于正则的字符串替换,没有做转义,太麻烦了
3mk实现了简单的 多级标题 图片 代码 引用功能 不支持嵌套 个人感觉还行 hhh
4之前写着玩的 以后不大可能更新了
const fs=require('fs');
const hp=require('http');
var blogs_url=[];//array to store all blogs url
function md_to_html(abs_src,abs_des){
var rules={
header:/^ *(#{1,6}) *([^\n]+?) *#* *(?:\n+|$)/g, //?:是为因为()是为了表示优先级而不是为了创建一个匹配组,所以用?:来说明
quote:/^ *> ([^\n]+?) *(?:\n+|$)/g,
img:/!\[.*\]\((.*\/)([^\n]+?\.[^\n]+?)\)/,
normal:/^([^\n]+?) *(?:\n+|$)/g,
code:/^```/,
bold:/(\*{2})([^\n]+?)(\*{2})/
}
fs.readFile(abs_src,{encoding:'utf-8'},(err,data)=>{
var content=data;
var blocks=content.split('\r\n');
var code_block_flag=1;
for(var x in blocks){
if(blocks[x]){
if(rules.code.exec(blocks[x])){
blocks[x]=(code_block_flag===1?'<pre style=\"background-color:black;color:white;white-space:pre-wrap\">':'</pre>');
//console.log(code_block_flag===1?'<p style=\"background-color:black;color:white\"><pre>':'</pre></p>');
code_block_flag*=-1;
continue;
}
if(code_block_flag===1){
var header=rules.header.exec(blocks[x]);
if(header){
var header_content=header[2];
h_size=header[1].length;
h_size=String(h_size);
blocks[x]=`<h${h_size}>${header_content}</h${h_size}>`;
continue;//直接下一次循环,不支持嵌套
}
var quote=rules.header.exec(blocks[x]);
if(quote){
quote=quote[1];
blocks[x]=`<p><cite>${quote}</cite></p>`;
continue;
}
blocks[x]=`<p>${blocks[x]}</p>`
blocks[x]=blocks[x].replace(rules.bold,"<strong>$2</strong>")
blocks[x]=blocks[x].split('').map((x)=>{
if(x.charCodeAt===8203){
return '  ';
}else if(x===' '){
return ' ';
}else{
return x;
}
}).join('');
//blocks[x]=blocks[x].replace(' ',' ');
blocks[x]=blocks[x].replace(rules.img,`<img src=\"../img/$2\" />`);
}
}else{
blocks[x]='<br/>'
}
}
var template=`<html>
<head>
<meta charset=\"utf-8\">
<title>blog</title>
</head>
<body>
${blocks.join('\r\n')}
</body>
</html>`;
fs.writeFile(abs_des,template,()=>{
console.log(`${abs_des}写入完成`);
})
})
}
fs.readdir('d:/blog/',{withFileTypes:true},(err,files)=>{
var html_inner='';
html_inner= files.map((x)=>{
if(x.isFile()&&x.name.indexOf('.md')===x.name.length-3){
md_to_html(`d:/blog/${x.name}`,`d:/blog/html/${x.name.slice(0,x.name.length-3)}.html`);
blogs_url.push(`${x.name.slice(0,x.name.length-3)}.html`);
return `<p><a href=\'./${x.name.slice(0,x.name.length-3)}.html\'>${x.name.slice(0,x.name.length-3)}</a></p>`;
}else{
return '';
}
}).join('\r\n');
var template=`<html>
<head>
<meta charset=\"utf-8\">
<title>blog</title>
</head>
<body>
${html_inner}
</body>
</html>`;
fs.writeFile('d:/blog/html/index.html',template,()=>{
console.log('写入完成');
})
})
hp.createServer((request,response)=>{
var {url}=request;
var real_url=decodeURIComponent(url);
var isImg=real_url.indexOf('/img/')===0;
console.log(real_url.indexOf('/img/'));
var check=blogs_url.find((x)=>{
if( '/'+x===real_url || isImg) return true;
else return false;
})
if(check){
if(isImg){
fs.readFile('d:/blog/html'+real_url,(err,data)=>{
response.write(data)
response.end();
})
}else{
fs.readFile('d:/blog/html'+real_url,{encoding:'utf-8'},(err,data)=>{
response.write(data);
response.end();
})
}
}else{
fs.readFile('d:/blog/html/index.html',{encoding:'utf-8'},(err,data)=>{
response.write(data);
response.end();
})
}
}).listen(80);
